下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 139.226.113.238 8090 高匿名 HTTP w397090770 10年前 (2015-05-12) 13693℃ 0评论1喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第一篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-15) 12516℃ 2评论10喜欢
Apache Kafka 从 0.11.0.0 版本开始支持在消息中添加 header 信息,具体参见 KAFKA-4208。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文将介绍如何使用 spring-kafka 在 Kafka Message 中添加或者读取自定义 headers。本文使用各个系统的版本为:Spring Kafka: 2.1.4.RELEASESpring Boot: 2.0.0.RELEASEApache Kafka: kafka w397090770 7年前 (2018-05-13) 4790℃ 0评论0喜欢
今天我将介绍如何在Java工程使用Scala代码。对于那些想在真实场景中尝试使用Scala的开发人员来说,会非常有意思。这和你项目中有什么类型的东西毫无关系:不管是Spring还是Spark还是别的。我们废话少说,开始吧。抽象Java Maven项工程 这里我们使用Maven来管理我们的Java项目,项目的结果如下所示:如果想及时了解Spa w397090770 8年前 (2017-01-01) 9851℃ 0评论24喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存 w397090770 9年前 (2016-02-05) 10264℃ 1评论12喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 9年前 (2016-01-17) 22981℃ 0评论23喜欢
前提条件:安装好相应版本的Hadoop(可以参见《在Fedora上部署Hadoop2.2.0伪分布式平台》)、安装好JDK1.6或以上版本(可以参见《如何在Linux平台命令行环境下安装Java1.6》) Hive的下载地址:http://archive.apache.org/dist/hive/,你可以选择你适合的版本去下载。本博客下载的Hive版本为0.8.0。你可以运行下面的命令去下载Hive,并解压:[ w397090770 11年前 (2013-11-01) 15357℃ 6评论3喜欢
SBT默认的日志级别是Info,我们可以根据自己的需要去设置它的默认日志级别,比如我们在开发过程中,就可以打开Debug日志级别,这样可以看出SBT是如何工作的。SBT的日志级别在sbt.Level类里面定义:[code lang="scala"]object Level extends Enumeration{ val Debug = Value(1, "debug") val Info = Value(2, "info") val Warn = Value(3, "warn&q w397090770 9年前 (2015-12-24) 3459℃ 0评论8喜欢
搜索API允许开发者执行搜索查询,返回匹配查询的搜索结果。这既可以通过查询字符串也可以通过查询体实现。多索引多类型所有的搜索API都可以跨多个类型使用,也可以通过多索引语法跨索引使用。例如,我们可以搜索twitter索引的跨类型的所有文档。[code lang="java"]$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'[/ zz~~ 8年前 (2016-09-22) 1674℃ 0评论2喜欢
现象大家在使用 Apache Spark 2.x 的时候可能会遇到这种现象:虽然我们的 Spark Jobs 已经全部完成了,但是我们的程序却还在执行。比如我们使用 Spark SQL 去执行一些 SQL,这个 SQL 在最后生成了大量的文件。然后我们可以看到,这个 SQL 所有的 Spark Jobs 其实已经运行完成了,但是这个查询语句还在运行。通过日志,我们可以看到 driver w397090770 6年前 (2019-01-14) 4244℃ 0评论18喜欢
什么是数据迁移Apache Kafka 对于数据迁移的官方说法是分区重分配。即重新分配分区在集群的分布情况。官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作。其底层实现主要有如下三步: 通过副本复制的机制将老节点上的分区搬迁到新的节点上。 然后再将Leader切换到新的节点。 最后删除老节点上的分区。重分 zz~~ 3年前 (2021-09-24) 903℃ 0评论5喜欢
本书于2015年03月出版,全书共104页,这里提供的是本书完整版。 w397090770 9年前 (2015-08-21) 1812℃ 0评论5喜欢
前言Facebook 的数据仓库构建在 HDFS 集群之上。在很早之前,为了能够方便分析存储在 Hadoop 上的数据,Facebook 开发了 Hive 系统,使得科学家和分析师可以使用 SQL 来方便的进行数据分析,但是 Hive 使用的是 MapReduce 作为底层的计算框架,随着数据分析的场景和数据量越来越大,Hive 的分析速度越来越慢,可能得花费数小时才能完成 w397090770 4年前 (2020-08-09) 1629℃ 0评论4喜欢
Hive on Spark功能目前只增加下面九个参数,具体含义可以参见下面介绍。hive.spark.client.future.timeout Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is sec if not specified. Timeout for requests from Hive client to remote Spark driver.hive.spark.job.mo w397090770 9年前 (2015-12-07) 24605℃ 2评论11喜欢
如果你使用 Spark RDD 或者 DataFrame 编写程序,我们可以通过 coalesce 或 repartition 来修改程序的并行度:[code lang="scala"]val data = sc.newAPIHadoopFile(xxx).coalesce(2).map(xxxx)或val data = sc.newAPIHadoopFile(xxx).repartition(2).map(xxxx)val df = spark.read.json("/user/iteblog/json").repartition(4).map(xxxx)val df = spark.read.json("/user/iteblog/json").coalesce(4).map(x w397090770 6年前 (2019-01-24) 8194℃ 0评论12喜欢
在Hive0.11.0版本新引进了一个新的特性,也就是当用户将Hive查询结果输出到文件,用户可以指定列的分割符,而在之前的版本是不能指定列之间的分隔符,这样给我们带来了很大的不变,在Hive0.11.0之前版本我们一般是这样用的:[code lang="JAVA"]hive> insert overwrite local directory '/home/wyp/Documents/result'hive> select * from test;[/code] w397090770 11年前 (2013-11-04) 21072℃ 9评论10喜欢
理论上,在Hadoop 1.x上开发的Mapreduce程序可以在Hadoop 2.x上面运行,Hadoop2.x类库对Hadoop1.x程序的兼容性主要体现在以下几点: 二进制兼容:利用mapred API开发以及编译程序可以直接在Hadoop 2.x运行,不需要重新编译; 源码兼容:利用mapreduce API开发的程序, 需要在Hadoop 2.x上重新编译才能运行; 不兼容部分:mradmin w397090770 11年前 (2013-12-10) 6516℃ 1评论4喜欢
本文详细地介绍了如何将Hadoop上的Mapreduce程序转换成Spark的应用程序。有兴趣的可以参考一下:The key to getting the most out of Spark is to understand the differences between its RDD API and the original Mapper and Reducer API.Venerable MapReduce has been Apache Hadoop‘s work-horse computation paradigm since its inception. It is ideal for the kinds of work for which Hadoop was originally des w397090770 10年前 (2014-09-07) 6441℃ 1评论9喜欢
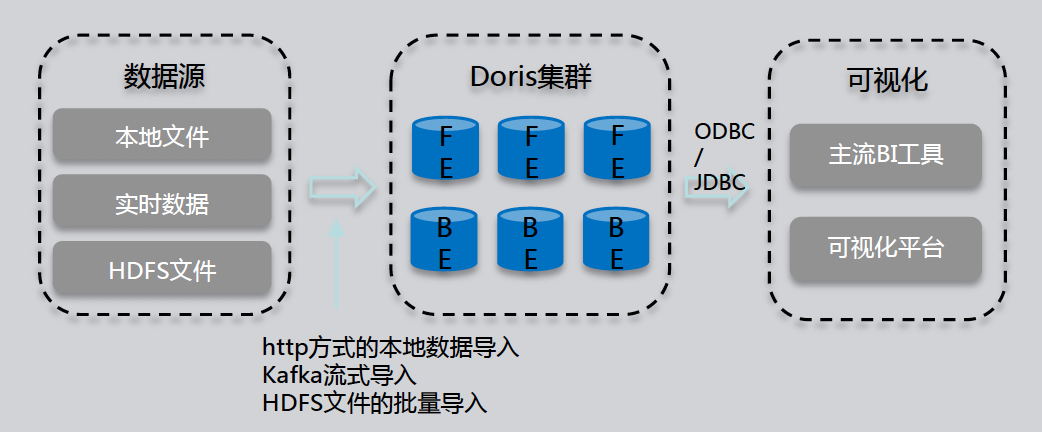
Apache Doris 简介Doris(原百度 Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在 2017 年开源,2018 年 8 月进入 Apache 孵化器。本次将主要从以下三部分介绍 Apache Doris.Doris 定位:即 Doris 所要面临的业务场景及解决的问题Doris 关键技术Doris 案例介绍01 Doris 定位实时数据仓库 Doris产品定位我们首先看一下 w397090770 5年前 (2019-12-11) 2968℃ 0评论4喜欢
即日起,关注@Spark技术博客 及@ 一位微博好友并转发本文章到微博有机会获取《Spark大数据分析实战》:/archives/1590。3月12日在微博抽奖平台抽取1位同学并赠送此书。本活动已经结束,抽奖信息已经在新浪微博抽奖平台公布 《Spark大数据分析实战》由高彦杰和倪亚宇编写,通过典型数据分析应用场景、算法与系统架构,结 w397090770 9年前 (2016-03-02) 8541℃ 0评论44喜欢
highlight.js是一款轻量级的Web代码语法高亮库,它主要有以下几个特点: (1)、支持118种语言(看这里https://github.com/isagalaev/highlight.js/tree/master/src/languages)和54中样式(看这里https://github.com/isagalaev/highlight.js/tree/master/src/styles); (2)、可以自动检测编程语言; (3)、同时为多种编程语言代码高亮; (4) w397090770 10年前 (2015-04-16) 14252℃ 0评论13喜欢
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集 w397090770 6年前 (2019-05-26) 5136℃ 1评论14喜欢
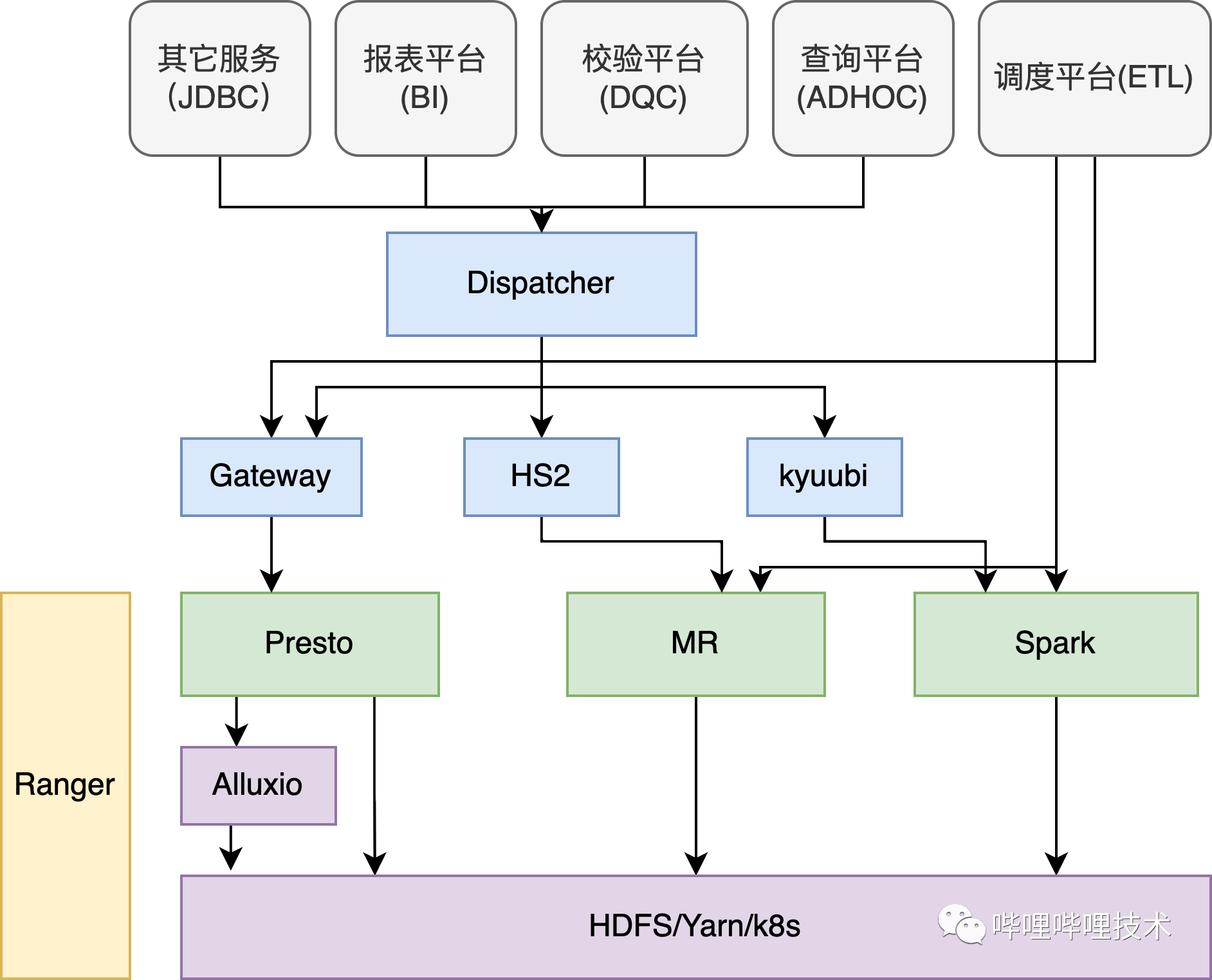
架构B站SQL On Hadoop 整体架构在介绍Presto在B站的实践之前,先从整体来看看SQL在B站的使用情况,在B站的离线平台,核心由三大计算引擎Presto、Spark、Hive以及分布式存储系统HDFS和调度系统Yarn组成。如下架构图所示,我们的ADHOC、BI、DQC以及数据探查等服务都是通过自研的Dispatcher路由服务来进行统一SQL调度,Dispatcher会结合查询 w397090770 3年前 (2022-04-14) 1907℃ 0评论4喜欢
本书作者 Denny Lee, Tathagata Das, Vini Jaiswal,预计2022年4月出版,出版社 O'Reilly Media, Inc.,ISBN:9781098104528分析和机器学习模型的好坏取决于它们所依赖的数据。查询处理过的数据并从中获得见解需要一个健壮的数据管道——以及一个有效的存储解决方案,以确保数据质量、数据完整性和性能。本指南向您介绍 Delta Lake,这是一种开 w397090770 4年前 (2021-05-27) 579℃ 0评论2喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16855℃ 3评论45喜欢
Hive 1.2.1源码编译依赖的Hadoop版本必须最少是2.6.0,因为里面用到了Hadoop的org.apache.hadoop.crypto.key.KeyProvider和org.apache.hadoop.crypto.key.KeyProviderFactory两个类,而这两个类在Hadoop 2.6.0才出现,否者会出现以下编译错误:[ERROR] /home/q/spark/apache-hive-1.2.1-src/shims/0.23/src/main/java/org/apache/hadoop/hive/shims/Hadoop23Shims.java:[43,36] package org.apache.hadoop.cry w397090770 9年前 (2015-11-11) 13663℃ 11评论6喜欢
今天 Apache Kafka 项目的 2.0.0 版本正式发布了!距离 1.0 版本的发布,相距还不到一年。这一年不论是社区还是 Confluent 内部对于到底 Kafka 要向哪里发展都有很多讨论:从最初的标准消息系统,到现如今成为一个完整的包括导入导出和处理的流数据平台,从 0.8.2 一直到 1.0 版本,很多新特性和新部件被不断添加。但同时更重要的,关于 w397090770 6年前 (2018-06-28) 5278℃ 0评论6喜欢
我们知道,编写Scala程序的时候可以使用下面两种方法之一:[code lang="scala"]object IteblogTest extends App { //ToDo}object IteblogTest{ def main(args: Array[String]): Unit = { //ToDo }}[/code] 上面的两种方法都可以运行程序,但是在Spark中,第一种方法有时可不会正确的运行(出现异常或者是数据不见了)。比如下面的代码运 w397090770 9年前 (2015-12-10) 5313℃ 0评论5喜欢
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护Kafka的读偏移量,而Spark Streaming系统并没有将这个消费的偏移量发送到Zookeeper中, w397090770 10年前 (2015-06-02) 25704℃ 36评论22喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展方向奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一 w397090770 9年前 (2016-05-24) 13080℃ 0评论26喜欢